
운영체제 (4) - Threads
2024년 1학기 운영체제 수업을 듣고 정리한 내용입니다. 수업 교재는 운영체제 - 내부구조 및 설계원리 8 판입니다.
Processes and Threads
프로세스는 실행되고 있는 프로그램으로 실행의 단위로 볼 수 있지만 자원 할당의 단위로도 볼 수 있다. 멀티스레딩 시스템에서는 실행의 단위를 스레드로, 자원 할당의 단위를 프로세스로 취급한다.
Multithreading
실행의 단위가 프로세스인 시스템에서는 한 프로세스가 필요에 따라서 다른 자식 프로세스를 생성한 다음 동시에 작업을 했지만, 실행의 단위가 스레드인 시스템에서는 한 프로세스가 여러 스레드를 생성하여 동시에 작업을 한다. 이것이 멀티스레딩 시스템이다.
예를 들어 MS-DOS는 한 프로세스에 한 스레드로 동작하는 시스템이다. UNIX는 다수의 프로세스가 각각 하나의 스레드를 가지는 것으로 볼 수 있고, 윈도우나 솔라리스같은 시스템들은 다수의 프로세스가 여러 스레드를 통해 동시에 작업을 수행하는 시스템이다.
Process Model
멀티스레딩 시스템에서 프로세스는 자원 할당의 단위이다. 따라서 프로세스 모델에서 자원과 관련된 정보들은 프로세스가 갖게 된다. 반면 스레드는 실행의 단위이므로, 이전에 공부했었던 프로세스 모델중에 실행에 필요한 정보들은 각 스레드마다 따로 존재해야한다.
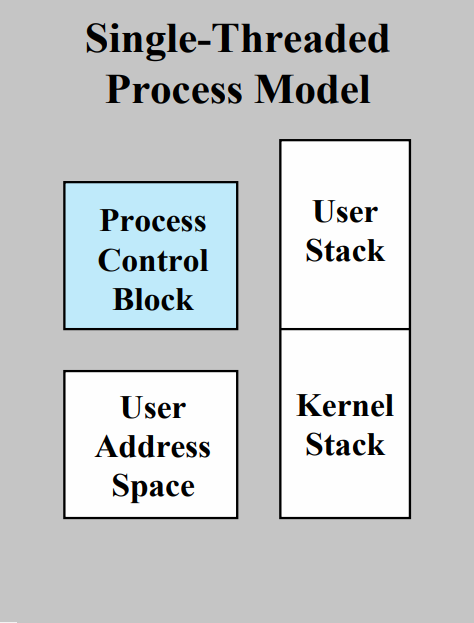
싱글스레드인 프로세스는 이전에 보았던 프로세스 모델과 동일하다.
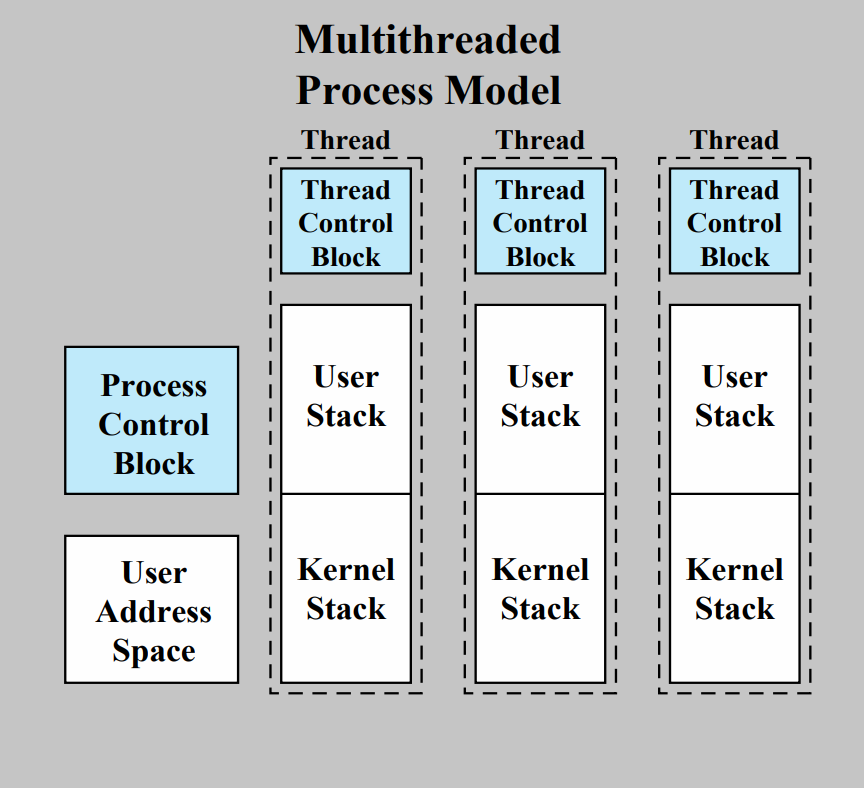
멀티스레딩 시스템에서는 위 사진처럼 Process Control Block(자원 할당과 관련된 정보들)과 Thread Control Block(실행과 관련된 정보들)이 분리된 모습이고, 각 스레드마다 유저 스택과 커널 스택이 들어있는 모습이다.
Process Control Block
PCB에서 자원 할당과 관련된 정보들이 여기에 들어있다.
- PID, PPID, UID
- 메모리 관리(프로세스에게 할당된 메모리 영영 관리)
- Resource Ownership / Utilization
- Inter-process Communication
- Process Privileges (프로세스에게 할당된 자원의 접근 권한)
- Process Table?
- Process Tree?
Thread Control Block
PCB에서 실행과 관련된 정보들만 뽑아내어 각 스레드마다 갖게 된다.
- Processor State Information
- 스케쥴링 및 상태 정보
- Data Structure 포인터(프로세스 포인터나 프로세스 트리 포인터 등)
Benefits
멀티스레딩 시스템의 이점은 이렇다.
- 동시에 실행을 시킬 수 있기 때문에 실행중에 Blocked 상태인 시간이 최소화된다.
- 다수의 프로세스를 생성/종료하는 것보다 다수의 스레드를 생성/종료하는 것이 훨씬 빠르다.
- 프로세스를 스위칭하는 것보다 스레드를 스위칭하는 것이 훨씬 빠르다.
- 프로세스 간 통신보다 스레드 간 통신이 훨씬 빠르다. 프로세는 커널을 거쳐 통신해야하지만, 스레드는 공유된 메모리 영역을 통해 통신할 수 있기 때문이다.
Thread states
프로세스가 실행중에 상태가 바뀌듯이, 스레드 또한 실행중에 상태가 바뀐다. 이전에 보았던 7가지 상태가 아닌 5가지 상태(Spawn, Ready, Running, Blocked, Finish)를 갖는다.
Suspend가 없는 이유?
Suspend는 메모리에서 하드디스크로 Swapping된 것인데, 자원의 위치가 변경되는 것이다. 자원과 관련된 것은 프로세스의 영역이기 때문에 스레드는 Swapping되지 않는다. 대신 프로세스가 Swapping되는 것이다.
User-level Thread
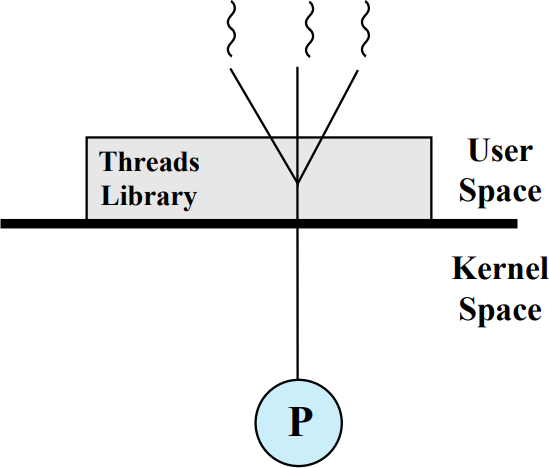
프로세스가 실행의 단위인 시스템에서 사용한다. 이 시스템에서 스레드는 유저 프로그램으로 존재하는 스레드 라이브러리에 의해 관리된다. 커널 영역에서는 하나의 프로세스로 보이지만 실제로는 여러 스레드가 실행되고 있는 중이다. 스레드 라이브러리는 커널과는 독립적으로 유저 영역에서 실행되기 때문에 특정 시스템에 국한되지 않고 여러 시스템에서 사용이 가능하다.
Change of state
유저레벨 스레드에서는 아래 사진처럼 3가지의 상태 변화가 일어난다.
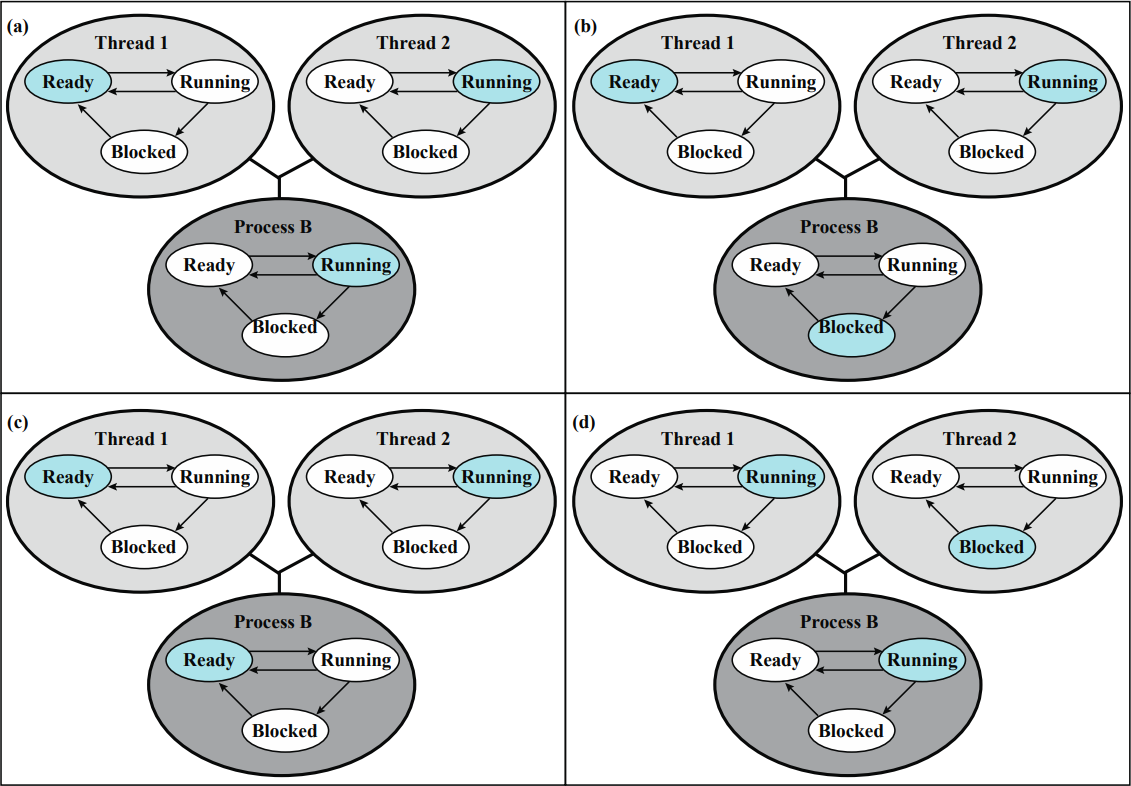
(a)는 커널이 프로세스 B를 실행하고 있는 상태이다. 실제로는 스레드 라이브러리에 의해 2번 스레드가 실행되고 있다.
(a) → (b)
프로세스 B가 Blocked 상태로 바뀌었다. 2번 스레드가 시스템 콜을 요청하여 프로세스가 Blocked된 것이다.주의할 점은 2번 스레드가 Blocked된게 아니라는 것인데, 시스템 콜을 요청하는 순간 커널이 프로세스를 Blocked시키기 때문이다.
커널은 유저레벨 스레드를 알 수 없기 때문에 프로세스를 Blocked 시킬 수만 있고 스레드를 Blocked 시킬 수 없다.(a) → (c)
프로세스 B가 다시 Ready 상태로 돌아간다. 프로세스가 Timeout되어 다시 Ready 상태로 돌아간 것이다.(a) → (d)
2번 스레드가 실행을 중단하고 1번 스레드가 실행된다. 스레드가 동기화를 위해 스스로를 Blocked 상태로 바꾼 것이다. 이 때에는 스레드 라이브러리에 의해 스레드 스위칭이 진행된다.
Kernel-level Thread
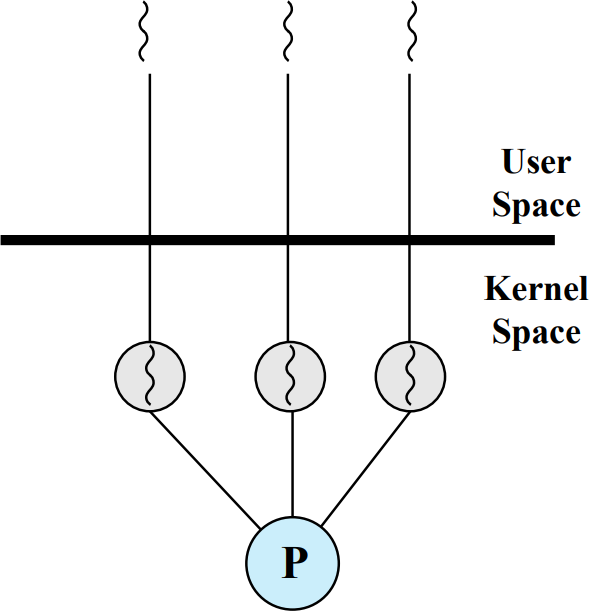
스레드 스위칭, 스케쥴링, 생성, 종료를 모두 커널이 담당하는 시스템이다. 다수의 프로세서로 여러 스레드를 동시에 실행한다. 만약 유저가 스레드를 3개 생성했다고 하면 실제로는 커널이 스레드를 3개 생성한 것이다. 스레드가 Blocked 상태가 되었다면 커널이 직접 스위칭하여 다른 스레드를 실행하게 된다. 커널이 직접 스위칭을 하는 것은 장점일 수도 단점일 수도 있지만 프로세스 스위칭보단 빨라서 상대적으로 좋다고 생각할 수 있다.
Combined Approaches for Threads
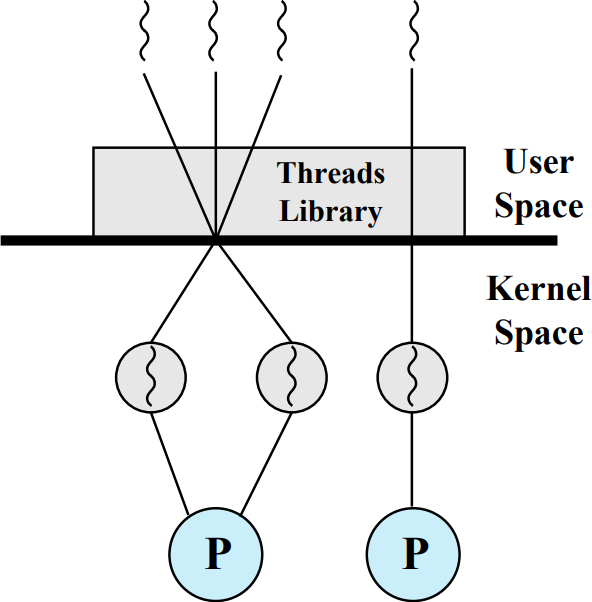
유저레벨 스레드와 커널레벨 스레드를 모두 사용하는 시스템이다. 커널레벨에서 여러 개의 스레드가 동시에 실행되지만, 유저레벨에 존재하는 스레드 라이브러리를 통해 더 많은 수의 유저레벨 스레드를 실행시킨다.
커널레벨 스레드의 장점인 동시 수행을 유지하면서 불필요한 스레드 스위칭과 스케쥴링을 하지 않는다. 왜냐하면 스레드 라이브러리에 의해 유저레벨에서 스위칭, 스케쥴링을 할 수 있기 때문이다. 또한 커널 레벨 스레드의 수를 최소로 관리할 수 있다.
Windows
윈도우는 커널레벨 멀티스레딩 시스템이다. 또한 객체지향 디자인을 사용하는 마이크로커널 아키텍쳐를 사용하고 있다.
윈도우는 스레드를 객체로 취급한다. 그리고 프로세스는 새로 생성되거나, 기존에 존재하는 프로세스를 복사하여 생성된다. 일단 프로세스를 생성하면 1개의 스레드가 자동으로 할당되고, 실행 중에 스레드가 다른 스레드를 생성할 수 있다. 또한 스레드 역시 실행의 단위로 여러 상태 큐에 담긴다. 마지막으로, 프로세스와 스레드 모두 동기화 툴을 갖는 특징이 있다.
Process Attributes
윈도우에서는 각 프로세스마다 여러 속성들을 갖는다.

중요한 속성들만 보면 이렇다.
| 속성 | 설명 |
|---|---|
| Base priority | 프로세스에 주어진 작업에 따른 우선순위 |
| Default processor affinity | 멀티 프로세스 시스템에서 프로세스가 실행되길 원하는 CPU의 집합 |
| Quota limits | 프로세스가 사용가능한 자원의 최대 크기? |
| Execution time | CPU 사용 시간 |
| I/O Counter | I/O 사용 시간 |
| VM operation counters | 가상 메모리 작업 횟수 |
| ... | ... |
윈도우는 우선순위 기반 스케쥴링을 하기 때문에, 프로세스마다 우선순위값(Base priority)을 할당받는다.
Q. 실행의 단위는 스레드인데, Default processor affinity값을 프로세스가 갖는 이유는?
CPU의 코어가 1개라고 생각해보자. 스레드를 실행시키게 되면 CPU안에 있는 캐시에 내가 찾았던 데이터 블록들이 그대로 남아있을 것이다. (지역성의 원리에 의해 캐시를 hit할 수 있는 확률이 높다.)
반대로 CPU의 코어가 굉장히 많다고 생각해보자. 스레드가 여러 CPU를 오가면서 작업을 하게 되면, CPU안에 있는 캐시가 다른 스레드에 의해 오염되어 내가 찾고자 하는 데이터를 hit하지 못할 확률이 굉장히 높게 된다.
그러므로 CPU의 코어를 지정해서 실행할 수 있다면 캐시의 성능을 올릴 수 있게 된다. 따라서 프로세스는 Default process affinity 값을 통해 특정 코어들에서만 스레드를 실행하겠다고 명시함으로 성능을 올릴 수 있다.
Thread Attributes
스레드의 속성은 다음과 같다.
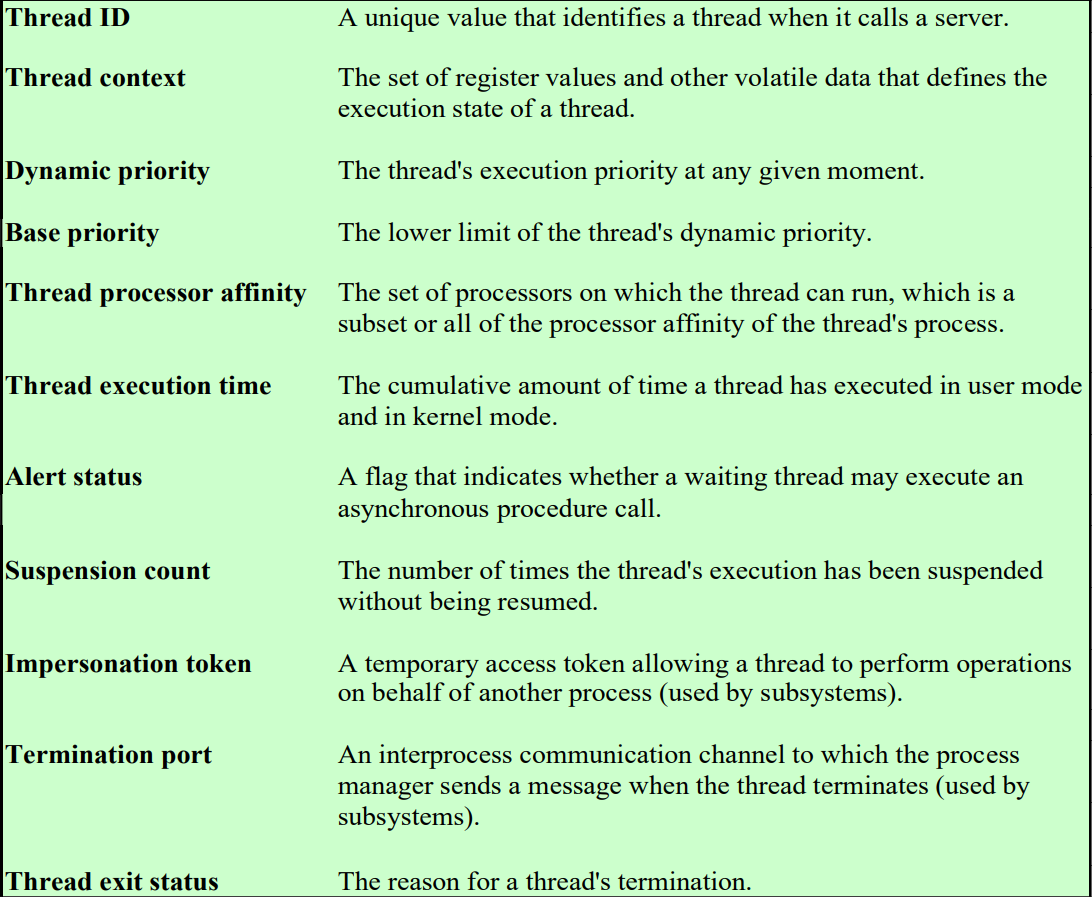
| 속성 | 설명 |
|---|---|
| Dynamic priority | OS가 스레드의 작업에 따라 부여한 우선순위. 이 값으로 스케쥴링이 이루어지며 Base priority보다 낮아지지 않는다. |
| Base priority | 프로세스의 Base priority값이다. |
| Thread processor affinity | 스레드가 실행되길 원하는 CPU의 집합. 프로세스의 값과 같거나 부분집합이다. |
| ... | ... |
Thread states
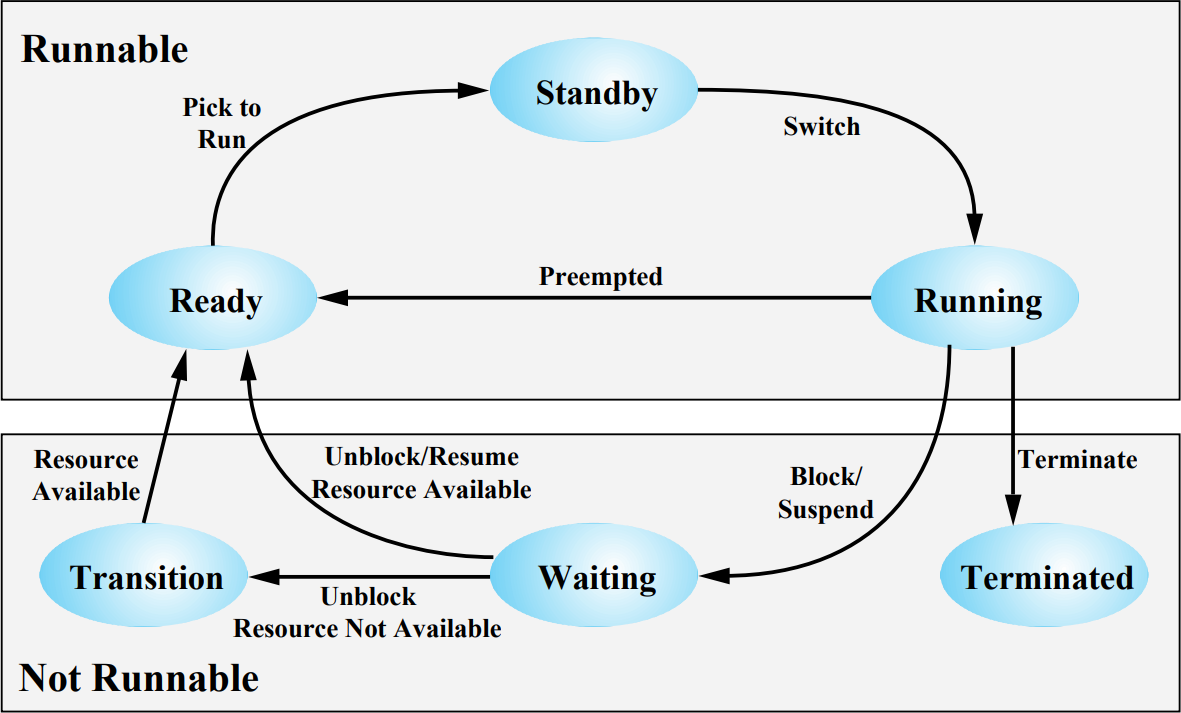
생성된 스레드는 Ready 상태로 존재한다. 여러 CPU가 동시에 Ready큐에서 스레드를 선택하려고 하면 한 스레드가 여러 CPU에서 실행되는 문제가 생긴다. 그래서 윈도우에서는 OS가 미리 실행할 스레드를 선택하여 Standby상태로 만든다(Pick to Run).
CPU는 Standby 상태인 스레드를 선택해 실행한다(Switch). 실행되고 있는 스레드는 Timeout이 되었거나, 더 높은 우선순위를 가진 스레드가 Standby 상태로 등장한다면 다시 Ready 상태로 돌아간다(Preempted).
윈도우는 Blocked 상태를 약간 다르게 관리하는데, 스레드가 중단되었다면 Waiting 상태가 된다. 여기서 Block/Suspend는 Timeout, 동기화, I/O 등에 의해 중단된 것을 의미한다. 이 때에는 하드디스크로 스레드가 이동했다는 것이 아니라 Unblocked 되기 까지 기다리는 상태를 말한다.
Unblocked 되었을 때 Resource Available이라면 곧바로 Ready 상태가 되지만, Resource Not Available이라면 Transition 상태가 된다. 다시 말해, 스레드가 Waiting 상태인데 프로세스가 swap-out되어 하드디스크로 이동해있다면, Resource Not Available이다. 반대로 **스레드가 Waiting 상태인데 프로세스가 여전히 메모리에 남아있다면 Resource Available인 것이다.
Solaris
솔라리스는 유저레벨 스레드와 커널레벨 스레드를 함께 사용한다.
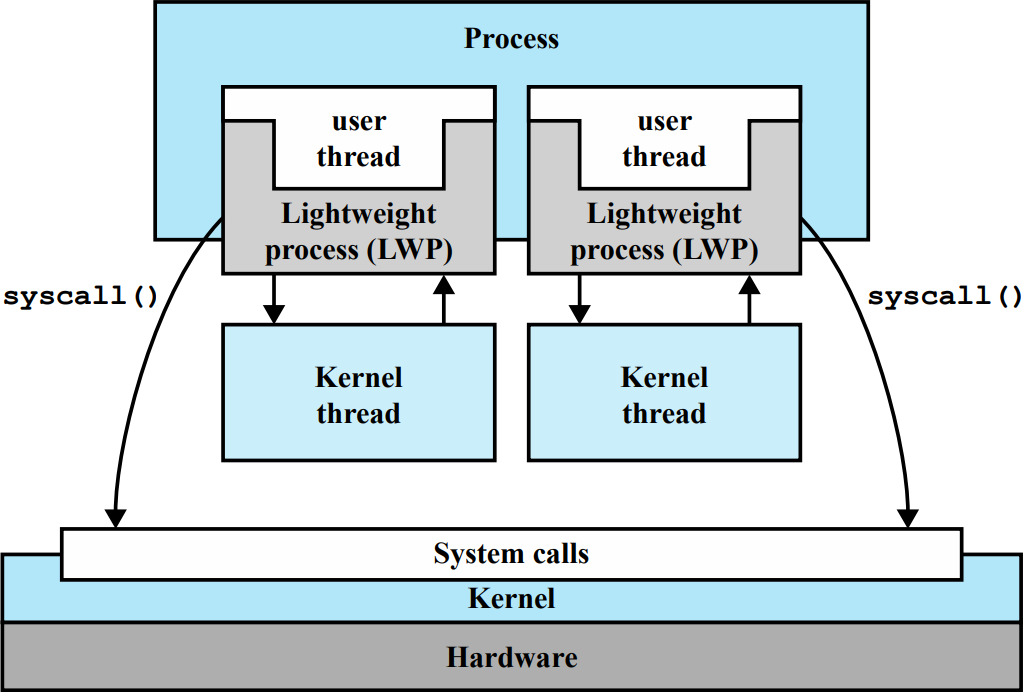
프로세스에서는 스레드 라이브러리에 의해 여러 유저레벨 스레드가 생성된다. 유저레벨 스레드들은 커널레벨 스레드에 올라가 작업하게 되는데, 그대로 올라가지 않고 Lightweight process(LWP)에 탑재되어 동작하게 된다. 커널 영역에서는 LWP가 보이기 때문에, 유저레벨 스레드와 커널레벨 스레드 사이에 LWP가 있는 특이한 구조로 동작한다.
솔라리스는 UNIX계열이므로 프로세스 스위칭을 최대한 적게 하기 위해 유저 영역과 커널 영역이 프로세스에 함께 존재한다. 유저레벨 스레드가 시스템 콜을 하게 되면 프로세스를 멈추게 만드는데, 이 때 커널을 거치지 않고 빠르게 스레드를 변경하기 위해 LWP를 사용한다.
사실 LWP가 필요한 명확한 이유를 찾기 힘들었다. 이 논문에서 자세한 내용을 볼 수 있다.
Thread states
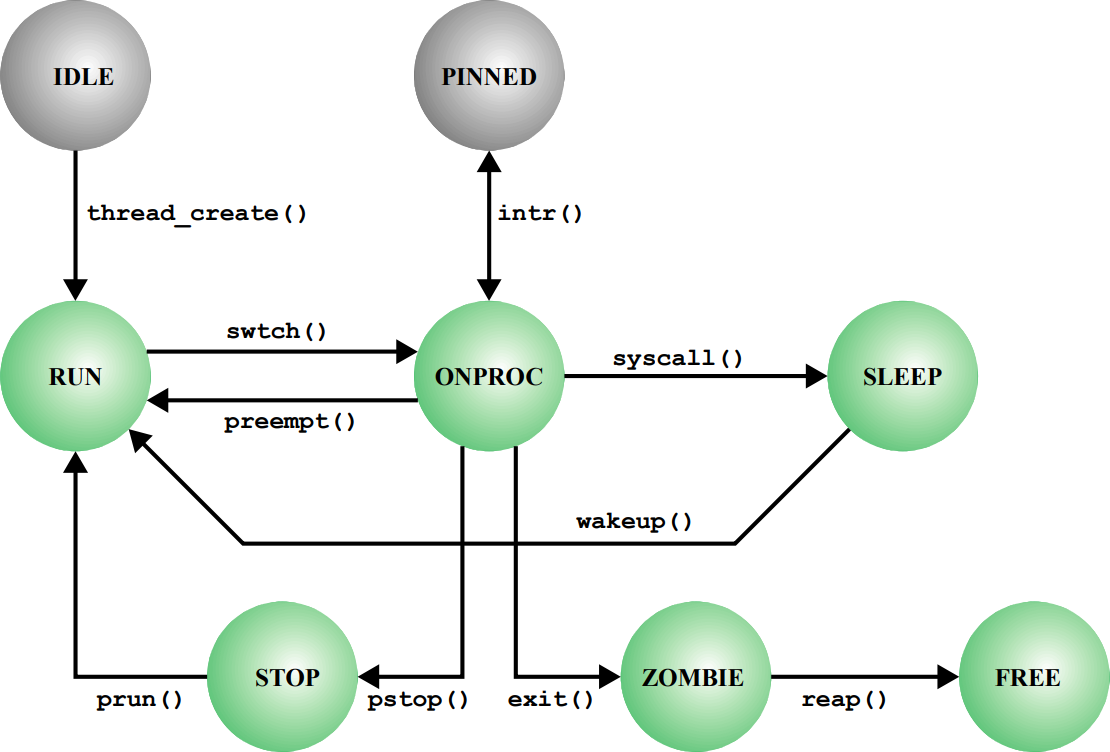
스레드가 생성되었지만 LWP와 매핑되지 않은 상태라면 IDLE 상태로 존재한다. 매핑이 되었다면 RUN 상태로 바뀌고, 이는 Ready 상태와 같다. 스레드가 실행중이라면 ONPROC 상태가 되고 우선순위가 높은 스레드가 등장하면 다시 RUN 상태로 바뀐다.
실행중인 스레드가 동기화 또는 Timeout에 의해 중단된다면 STOP 상태로 바뀐다. 반면 I/O 작업을 요청함으로 중단되었다면 SLEEP 상태가 된다.
스레드가 실행중인데 LWP와 매핑이 되지 않고 독립적인 커널 스레드(커널 작업만 하는 스레드)가 작업을 해야 하는 경우에는 PINNED 상태로 바뀐다. 이 상황에서는 현재 실행중인 CPU 옆에 핀으로 꽂아두고 커널 작업이 끝났을 때 다시 떼어와 작업을 한다는 맥락이다. 이렇게 하는 이유는 불필요한 스위칭을 막기 위할 뿐만 아니라 캐싱된 데이터를 놓치지 않기 위함이다.
스레드가 종료될 때에는 ZOMBIE 상태로 바뀐다. 이 때에는 스레드가 사용한 자원을 반납하기 전이고, 자원을 반납했다면 FREE 상태가 되어 테이블에만 존재하게 된다.
Linux
리눅스에서는 멀티스레드를 지원하지 않는다. 프로세스 기반 시스템인데, 스레드를 사용하는 것처럼 흉내를 내게 되었다.
프로세스 대신에 Task라는 단어를 사용한다. Task는 State, 스케쥴링 정보, Identifier, Interprocess communication 등 프로세스가 갖는 여러 정보들을 갖는다.
리눅스에서 Task를 만들려면 clone()또는 fork()를 사용해야한다. 두 명령어는 아래 사진과 같은 결과를 낸다.
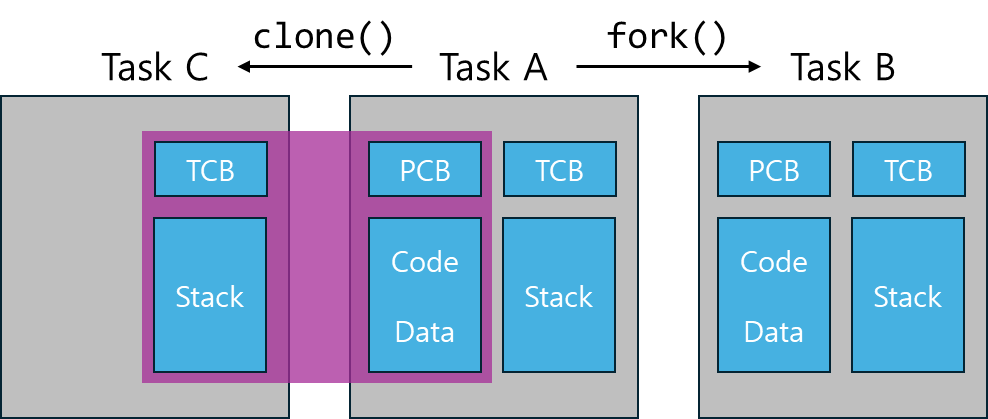
fork()는 Task를 복사하여 새로운 프로세스를 만들지만, clone()은 새로운 Task를 만들되 PCB와 코드 및 데이터는 공유되는 특성을 가진다. 스레드가 다른 스레드와 프로세스의 코드 및 데이터를 공유한다는 점이 같으므로 clone()을 사용하여 새로운 Task를 만들어 멀티스레딩을 사용하는 것처럼 흉내낼 수 있다.
Task states
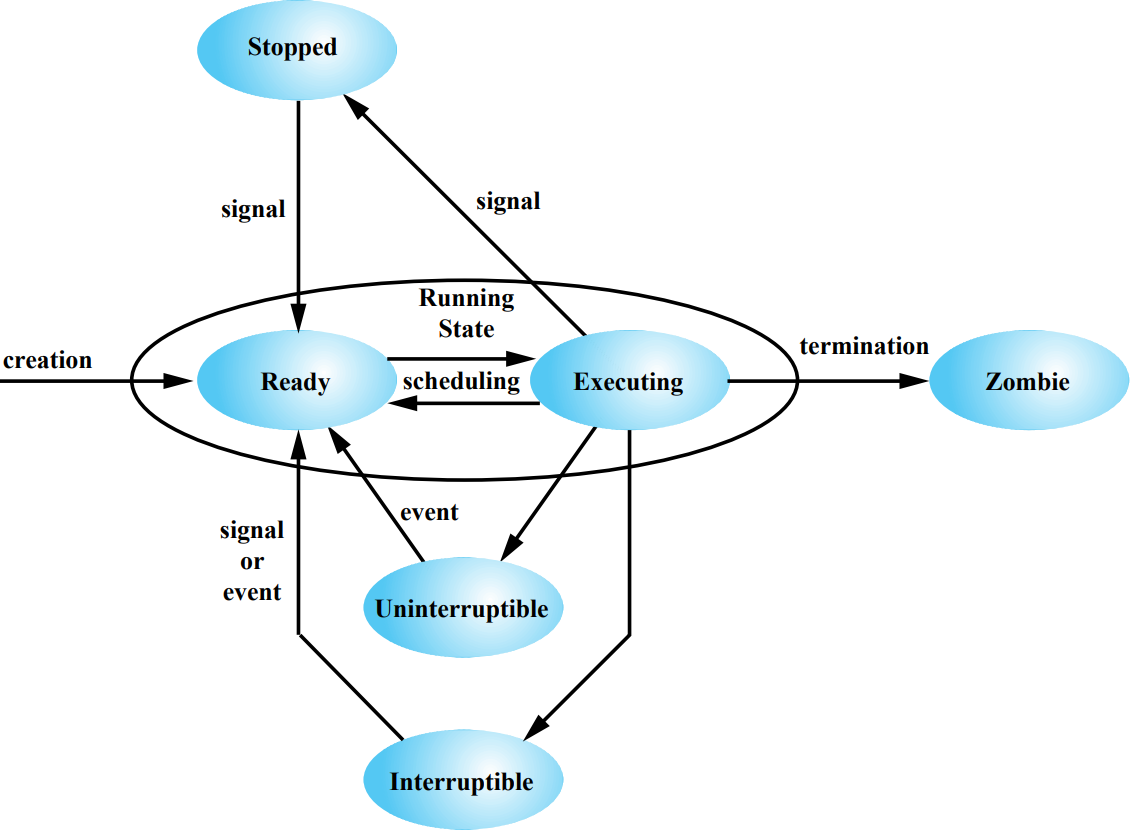
Task가 생성되면 Ready 상태가 된다. Task가 실행될 때에는 Executing 상태가 되고, Timeout이나 더 높은 우선순위의 Task가 등장하면 다시 Ready 상태로 돌아간다. 만약 I/O 작업이나 다른 이유에 의해 Blocked 상태가 되어야 한다면 Interruptible 또는 Uninterruptible 상태가 된다.
사용자가 보내는 Signal을 무시하고 오직 이벤트가 발생해야만 Unblocked될 수 있을 때 Uninterruptible 상태가 된다. 반대로 Interruptible 상태일 때는 사용자가 Signal을 보내거나 이벤트가 발생하면 Ready 상태로 간다. 사용자가 Signal을 보내는 경우의 대표적인 예시는 어떤 작업을 하라고 시켰는데 사용자가 작업을 중단하고 싶어서 Ctrl+C로 중단시키는 경우이다.
또한 Suspend되어 Task가 하드디스크로 가면 Stopped상태가 되고 다시 swap-in될 때 Ready 상태로 돌아온다.