
운영체제 (11) - I/O Management and Disk Scheduling
2024년 1학기 운영체제 수업을 듣고 정리한 내용입니다. 수업 교재는 운영체제 - 내부구조 및 설계원리 8 판입니다.
Disk Performance Parameters
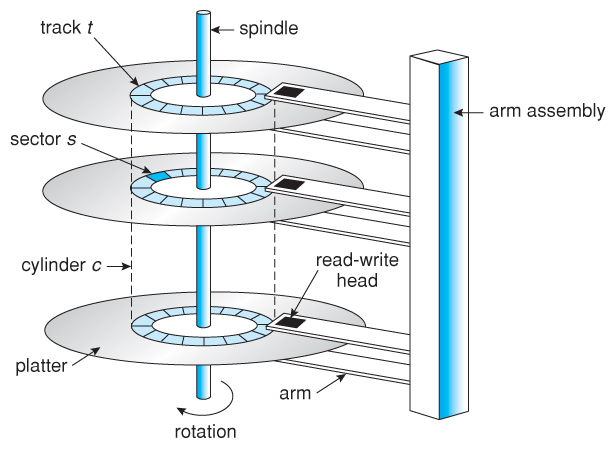
디스크 내부는 얇은 판이 여러 개 겹쳐져 있고 각 판 사이에 데이터를 읽는 헤드가 존재한다. 판을 회전시키거나 헤드를 앞뒤로 움직여 데이터를 읽는데, 헤드를 이동하는 시간(seek time)보다 판이 회전하는 시간이 월등히 빠르다. 또한 데이터를 읽는 시간은 굉장히 짧으므로 실제로 고려해야하는 것은 어떻게 헤드를 이동시키는가이다.
판은 수십개의 트랙이 겹쳐져 있고 헤드는 이 트랙을 왔다갔다하며 데이터를 읽는다.
예시로 0부터 200까지의 트랙이 있다고 가정하고, 다음의 트랙을 방문해야한다고 하자. 그리고 헤드의 시작 위치를 100으로 고정한다.
$$
62,138,61,91,171,187,108,149,30,43,40,42,89,183
$$
First-in First-out
- 요청이 도착한 순서대로 방문한다.
- Starvation이 없다.
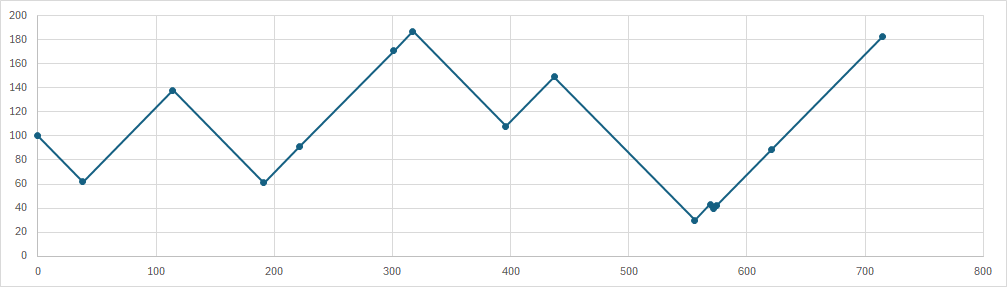
위 예제대로 실행하면 총 seek time은 715이다. 500초와 600초 사이에는 인접한 트랙에 있는 요청이 처리되지만, 그 외의 요청들을 보면 굉장히 이동 시간이 긴 모습을 볼 수 있다.
Shortest Service Time First
- 현재 헤드 위치에서 제일 가까운 트랙을 방문한다.
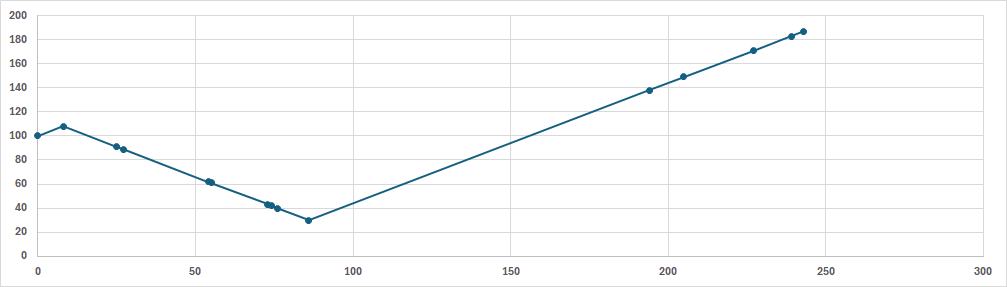
시작 위치가 100이므로 전체 요청중에 100과 제일 가까운 곳으로 방문한다. 전체 요청 중에 108이 제일 가까우므로 108을 방문한다. 108에서 가장 가까운 트랙은 91이 제일 가깝다. 91에서 가장 가까운 트랙은 89이다. 이렇게 현재 트랙에서 가장 가까운 트랙으로 이동하면서 탐색한다.
총 seek time은 243으로 FIFO에 비해 굉장히 짧다. 가장 Optimal하지만 Starvation이 발생할 가능성이 있다. 138은 두 번째로 도착한 요청이지만 200초에 가까운 시간에 탐색되는 모습을 볼 수 있다. 왜냐하면 헤드가 양쪽으로 이동할 수 있지만 가장 가까운 방향으로만 이동하기 때문에 상대적으로 헤드와 먼 트랙은 늦게 탐색되기 때문이다.
SCAN
- 현재 헤드 위치에서 제일 가까운 트랙을 방문한다. 그러나 한 쪽 방향으로만 이동하고, 더이상 이동할 트랙이 없을 경우에 방향을 바꿔 탐색한다.
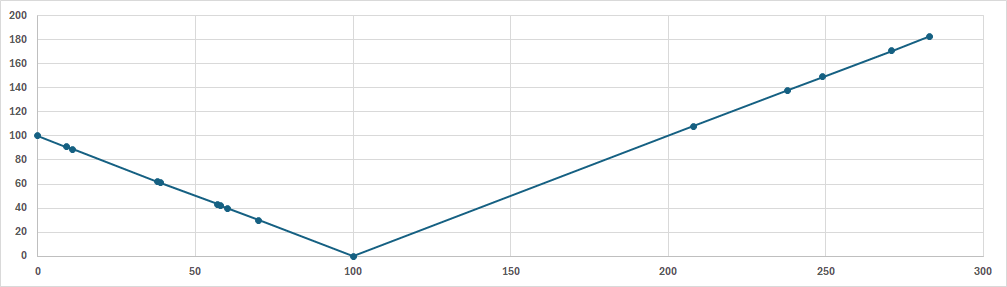
앞서 SSTF를 사용할 땐 100→108→91→...순으로 이동했지만 SCAN은 헤드의 방향을 고정하기 때문에 100→91→89→... 순으로 이동한다.100초쯤에 더이상 탐색할 트랙이 없다고 판단되어 방향을 바꿔 탐색하는 모습을 볼 수 있다.
총 seek time은 287초로 SSTF보다 오래 걸리지만 FIFO보다 좋은 모습을 보인다. 이 방법 또한 완전히 Fair하지 않고 Starvation의 가능성이 약간 있다. 50초 전후를 보면 특정 범위에 요청이 몰려 시간이 걸리는 모습을 볼 수 있다. 즉, 138과 같이 먼저 요청했지만 헤드 방향과 반대여서 늦게 처리될 수 있다는 것이다.
C-SCAN
- SCAN과 같이 탐색하는 방향은 고정이다. 그러나 더 이상 탐색할 트랙이 없다고 판단되면 반대편으로 돌아가 다시 탐색한다. Circular-SCAN이다.
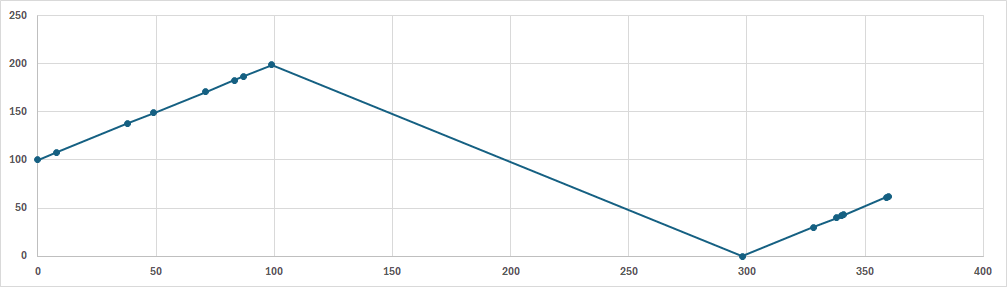
방향을 위로 고정하고 탐색한 모습이다. 100초에 더이상 탐색할 트랙이 없다고 판단되어 반대편으로 이동해(300초쯤) 다시 탐색하는 모습을 볼 수 있다. 100초부터 300초까지는 헤드를 반대편으로 돌리는 시간이므로 이 때에는 탐색을 하지 않는다.
탐색을 하지 않고 헤드를 돌려놓는 시간때문에 SCAN보다 느리지만 완전히 Fair한 방법이다. SCAN은 요청이 몰리면 특정 트랙은 seek time의 최대값이 바뀌지만, C-SCAN은 트랙 위치와는 관계 없이 seek time의 최대값이 일정하다.
N-Step SCAN
- 길이가 N인 큐를 사용한다. 요청이 들어오면 큐에 요청을 저장하고, 큐가 꽉 차면 다음 큐에 요청을 저장한다. 디스크는 큐에 담긴 요청을 SCAN으로 처리한다.
한 번에 N개만 처리하기 때문에 Starvation이 없다. 새로운 요청은 다음 큐에 쌓이므로 현재 큐에 있는 요청은 무조건 처리될 것으로 생각되기 때문이다.
N이 1이면 FIFO, N이 매우 큰 값이면 SCAN이므로 적절히 잘 설정하면 FIFO와 SCAN의 중간 성능을 보여준다.
FSCAN
- 두 개의 큐만 사용한다.
- 요청이 들어오면 큐에 요청을 저장한다. 디스크는 큐에 있는 요청을 SCAN으로 처리한다.
- 한 큐에 있는 요청을 처리할 때 다른 요청이 오면 다른 큐에 요청을 저장한다. 현재 처리중인 큐가 비었을 때 큐를 전환하여 처리한다.
N-step SCAN처럼 큐를 나눠 처리하기 때문에 Starvation이 없다.
그 외
Priority Scheduling
요청을 보낸 Task가 누구인지에 따라 우선순위를 고려한 처리 방법이다.
Last-In First-Out
자역성에 의해 헤드 근처에 있는 데이터를 요청할 것이므로 seek time을 줄일 수 있는 처리 방법이다.
RAID
RAID는 Redendant Array of Independent Disks의 줄임말로 여러 물리적 디스크들을 하나의 논리적 디스크처럼 사용하는 방법이다. 하나의 디스크에 접근하려면 느리므로 여러 디스크에 나누어 저장함으로 액세스 시간을 줄이려는 기술이다.
여러 디스크에 데이터를 나누기 때문에 하나라도 고장이 난다면 전체 디스크가 쓸모없어지므로 복구 가능성이 중요해졌다.
RAID 0(non-redundant)
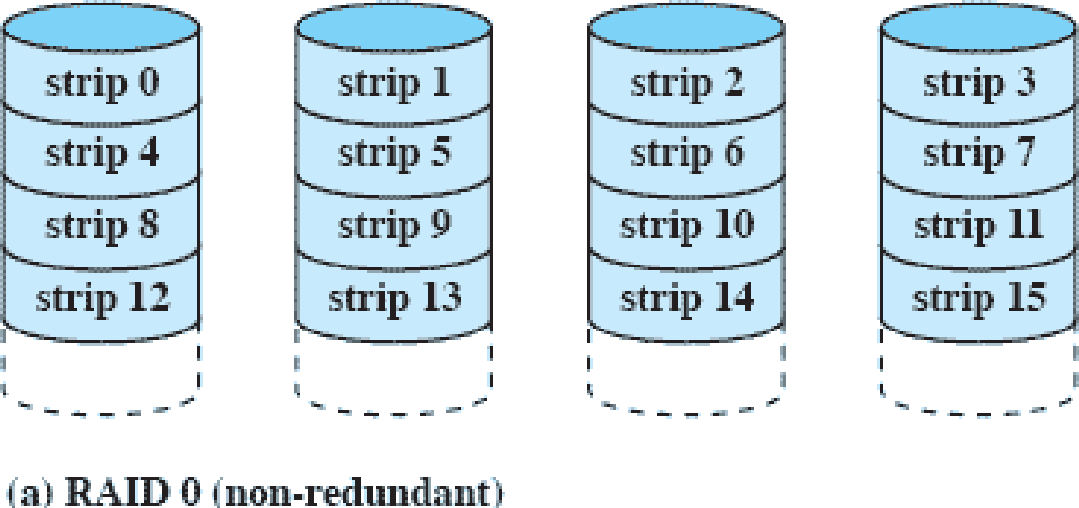
그냥 골고루 나누어 저장하는 방법이다. 초기에는 이렇게 나누기만하고 복구할 생각은 안한것 같다. 당연히 디스크 하나가 망가지면 전체가 망가지는 셈이다.
strip은 조각이라는 의미로 하나의 데이터를 쪼갠 것이다.
RAID 1(mirrored)
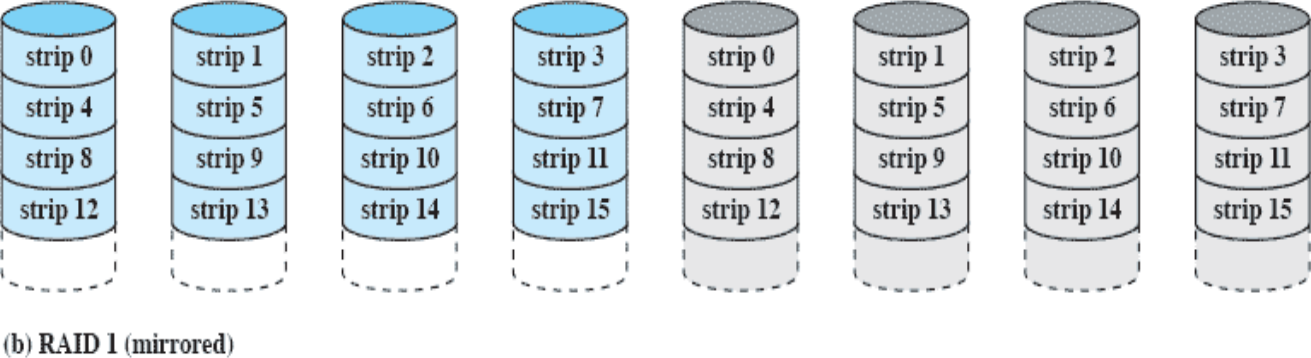
복구가능성을 올리기 위해 똑같은 개수의 디스크를 사용하여 복구 데이터를 넣어놓은 것이다. 읽을 땐 데이터 디스크(파란색)만 접근하고 복구 디스크(회색)은 쓰지 않는다. 데이터 디스크가 망가지면? 복구 디스크(회색)를 읽으면 된다.
복구가능성을 올리기 위해 RAID 0에서 비용을 두 배로 올렸지만 속도는 그대로다.
RAID 2(redundancy through hamming code)
Strip이 아닌 비트 단위로 저장한다. 복구 디스크는 해밍 코드를 사용하여 디스크 개수를 최적화한다.
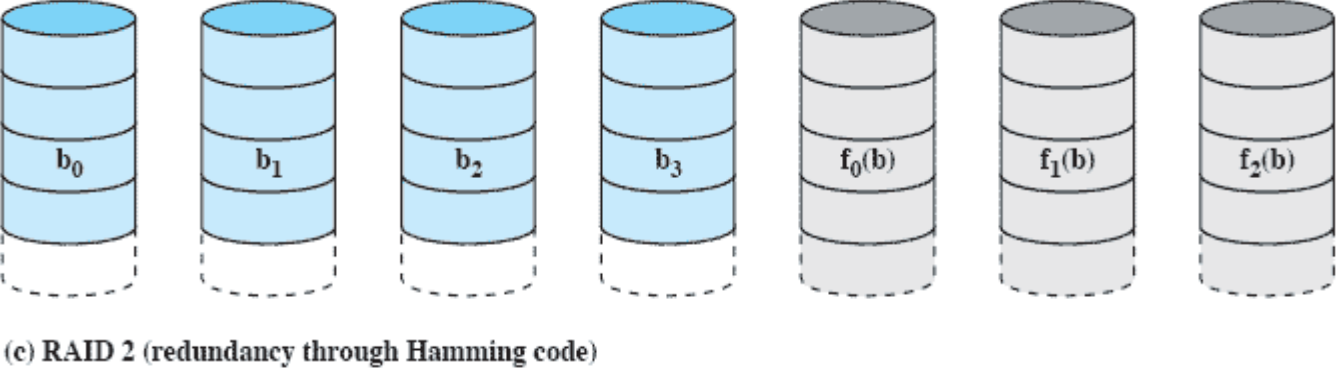
사진에서 볼 수 있듯이 데이터 디스크 개수가 4개인데 복구 디스크는 3개인 것을 볼 수 있다. 데이터 디스크 한 두개가 고장나도 해밍코드를 통해 복구 가능하다.
해밍코드
해밍코드 $C_i$는 각 데이터의 인덱스를 2진수화 했을 때 $2^i$번째 값이 1인 데이터들을 XOR한 값이다.
여기 블로그를 참고하면 더 좋을 것 같다. 필자도 이곳을 보고 공부했다.
https://dreamlog.tistory.com/578
https://blog.naver.com/ggggamang/221113176831
RAID 1보다 복구 디스크가 훨씬 줄어든다. 데이터 디스크가 14개일 때를 예로 들면 $2^3<14<2^4$이므로 복구 디스크는 5개만 필요하지만 RAID 1에서는 14개나 필요하다.
RAID 3(bit-interleaved parity)
패리티 비트를 사용해서 복구 디스크를 1개만 사용한다. 데이터 디스크 1개가 망가지면 복구할 수 있지만 2개 이상으로 망가지면 복구가 불가능하다.
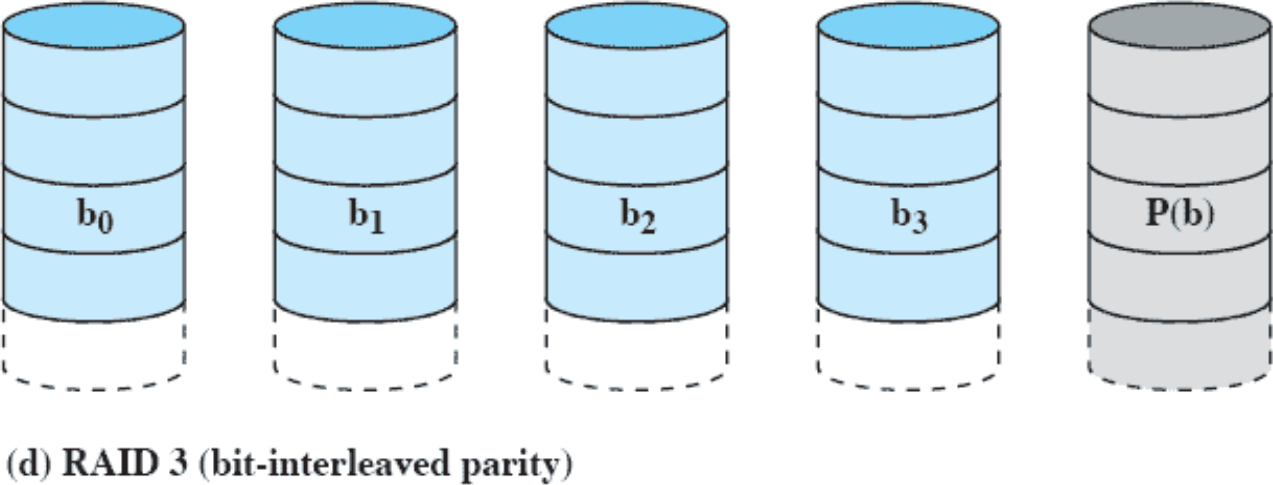
홀수 패리티는 1의 개수를 홀수로 만들기 위해 추가하는 것이고 짝수 패리티는 1의 개수를 짝수로 만들기 위해 추가하는 것이다.
RAID 4(block-level parity)
저장 단위를 비트 대신에 블럭으로 변경했다. 블럭 단위로 저장하고 복구 디스크에는 블럭 단위로 패리티 비트를 적용한다.
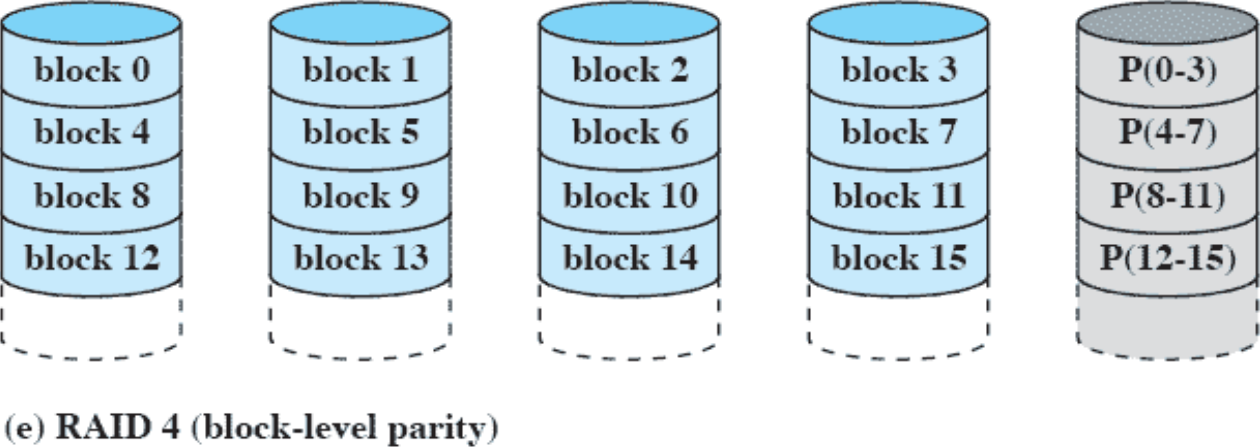
데이터 디스크에 쓰기 작업을 진행하면 복구 디스크에도 쓰기 작업을 해야하므로, 다른 데이터 디스크에 쓰기 작업을 했지만 복구 디스크에는 요청이 집중되는 모습이 나타난다.
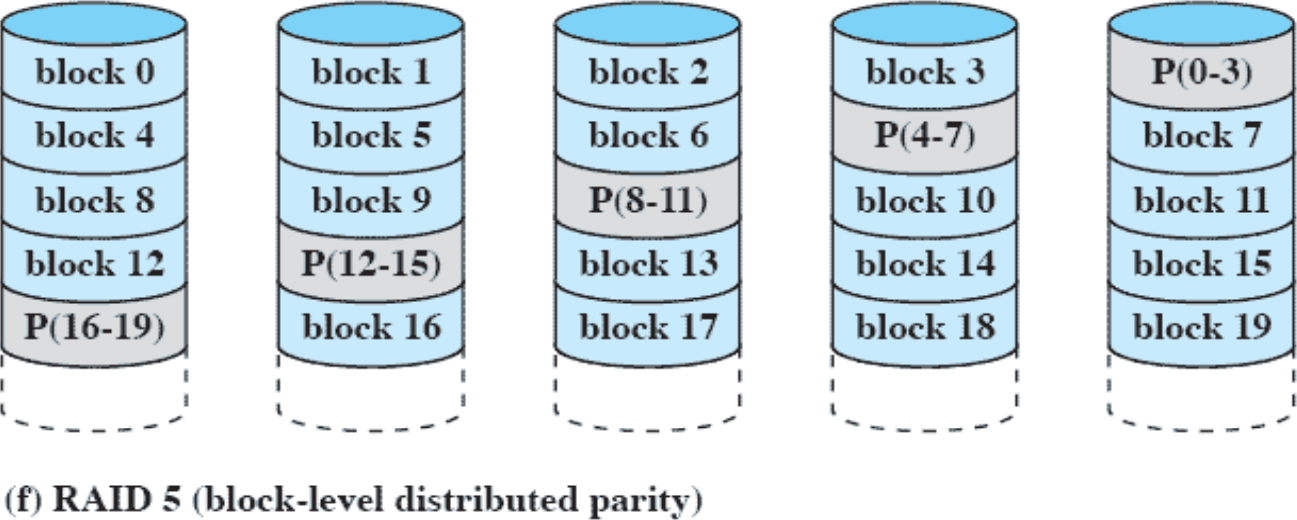
RAID 5(block-level distributed parity)
RAID 4에서 제기되었던 데이터 디스크보다 복구 디스크에 요청이 많이 쌓이는 문제를 해결하기 위해 복구 디스크에 담긴 데이터를 데이터 디스크 사이사이에 뿌려버렸다. 복구 디스크에 있는 블럭들을 여러 데이터 디스크 속으로 뿌려버렸기 때문에 요청 또한 분산되는 효과가 있다.
Disk Cache
디스크에서 읽어온 블럭들은 디스크 캐쉬에 저장된다. I/O 요청이 발생하면 먼저 디스크 캐쉬에 접근한 후 miss될 때에만 디스크를 읽는 작업을 하게 된다. 실제로는 지역성 때문에 hit하는 경우가 많다.
캐쉬 특성상 읽어온 블럭을 저장하고 기존에 있던 블럭을 버려야하는 상황이 발생한다. 이 때에는 제일 안 쓸것 같은 블럭을 버려야 한다.
Least Recently Used
제일 오래된 블럭을 버린다.
오래된 블럭을 찾기 위해 스택 자료구조를 사용한다. 방금 읽은 블럭은 또 쓰일 것이기 때문에 스택의 top으로 이동한다. 그러면 가장 오래된 블럭이 bottom에 남아있게 되고, 그 위치의 블럭을 버린다.
그러나 디스크에는 많은 프로세스가 접근하기 때문에, 각자 쓰는 블럭이 다르다. 즉, Optimal하진 않다.
Least Frequently Used
자주 사용하는 것을 유지하는 방법이다.
각 블럭마다 카운터를 두어 접근할 때마다 카운터를 누적한다. 버려야 할 상황이 오면 카운터의 값이 가장 낮은 블럭을 버린다.
그러나 방금 읽어온 블럭은 카운터 값이 1이므로 그 블럭을 버리는 문제가 발생한다.
Frequency-based Replacement
LRU와 LFU를 섞은 방법이다.
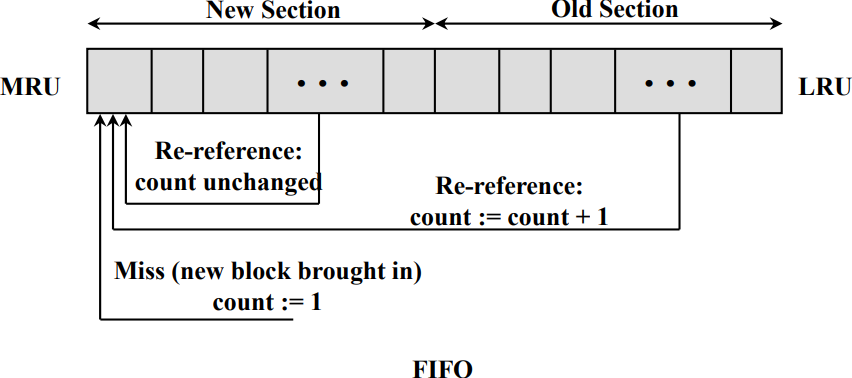
스택 자료구조를 사용한다. MRU는 Most Recently Used, LRU는 Least Recently Used의 줄임말이다. MRU와 가까운 New Section은 최근에 사용한 블럭들이고, LRU와 가까운 Old Section은 오래된 블럭들이다.
각 블럭들에는 카운터가 존재한다. Re-reference는 참조가 되었다는 뜻인데, New Section에 있는 블럭들을 참조할 경우 카운터는 바뀌지 않는다(집중적으로 사용되고 있다는 의미). 그러나 Old Section에 있는 블럭들을 참조하면 카운터가 누적된다(공통적으로 쓰이고 있다는 의미). 새로 블럭이 들어오면 카운터가 1인 상태로 MRU에 들어간다. 이렇게 하면 LRU와 가까운 Old section에 있는 블럭을 버림으로 오래된 블럭들을 쓰지 않을 수 있고, New Section에 새로운 블럭들을 추가함으로 막 추가된 블럭들을 버리지 않게 된다.
New Section에 들어온 블럭이 Old Section으로 간다면 카운터가 1이기 때문에 바로 버려진다. 그래서 Middle Section을 두고, 여기서 참조된다면 Old Section과 같이 카운터를 누적하고 top으로 보낸다.
실제로 버려질 블럭은 Old Section에서 선택된다. Old Section에서 카운터가 가장 낮은 블럭을 버리게 되는데, 카운터가 낮다는 것은 Old Section에서 New Section으로 잘 가지 않았다는 뜻이므로 집중적으로 쓰였다가 그렇지 않게 된 블럭들을 버린다는 의미이다.