2024년 2학기 멀티코어프로그래밍 수업을 듣고 정리한 내용입니다. 수업 교재는 Computer Architecture: A Quantitative Approach입니다.
Cache coherence
NUMA 구조에서 각 코어의 메모리(캐시)간 동기화가 필요하다고 했었다. 두 가지 속성이 존재한다.
Coherence
캐시를 읽으려고 하면 항상 최신의 값을 읽어오는 것.
두 프로세서가 한 캐시에 쓰기를 하게 되어 그 순서가 정해졌다면, 모든 프로세서들이 그 순서대로 값을 보아야 하는 것.
Consistency
한 프로세서가 값을 A위치에 쓴 다음 B위치에 썼다면, B 위치의 값이 새로 쓰였다는 것을 확인한 프로세서는 당연하게 A위치도 값이 바뀌었음을 확인할 수 있어야 하는 것.
Protocol
coherence를 지키기 위한 프로토콜은 두 가지가 있다.
Write-update
한 프로세서가 Write한다면 그 결과를 모든 프로세서에게 송신한다.
Write-invalidate
한 프로세서가 Write한다면 일단 다른 프로세서들에게 해당 주소값을 invalidate하도록 시키고, 나중에 값을 갱신하도록 한다.
Write-update는 모든 코어들의 캐시가 항상 일관된 상태를 유지하지만 한 번이라도 Write가 일어난다면 일관된 상태를 보장하기 위해 많은 비용이 들어간다. 반대로 Write-invalidate는 항상 일관된 상태를 보장하지는 않지만, 적은 비용을 사용하여 동기화를 유지하려고 한다.
Write-update는 비용이 매우 크기 때문에, Write-invalidate를 주로 사용한다.
MESI
Write-invalidate를 사용한다면 캐시의 각 주소는 다음과 같은 상태를 갖는다.
| 상태 | 설명 |
|---|---|
| Modified | 데이터가 수정된 상태 |
| Exclusive | 유일한 복사본, 캐시가 메모리와 동일한 상태 |
| Shared | 데이터가 두 개 이상의 캐시에 복사된 상태 |
| Invalid | 데이터가 유효하지 않은 상태 |
각 캐시는 위와 같은 상태를 가지기 때문에 각 캐시블록마다 상태를 나타내는 비트(valid, dirty)가 추가로 들어간다.
Write-invalidate를 사용할 때, 캐시에 변화가 일어날 경우 이를 처리하는 방법은 두 가지가 있다.
Snooping
데이터를 염탐하여 정보를 얻는 것이라는 의미로 스누핑을 쓰는데, 그 스누핑과 같은 의미로 쓰인다. 버스를 수신하면서 캐시에 변화가 일어나는지 감시하고 이벤트가 발생하여 버스에 이벤트가 전파된다면 그 때 캐시를 수정하는 방식이다. 그러므로 항상 버스를 관찰(스누핑)하고 있어야 한다.
Directory-based
메모리 블럭에 할당된 별도 공간(디렉토리)에 메모리를 읽어간 프로세서 목록을 저장한다. 해당 메모리에 이벤트가 발생하면 디렉토리를 조회하여 메모리를 읽어간 프로세서에게 이벤트를 보내는 방법이다. 스누핑에 비해 비용은 줄겠지만 공간적 오버헤드가 발생한다.
데이터를 읽는 방법
Write-through
항상 메모리로부터 최신의 값을 읽어온다. 메모리에 접근하므로 버스 사용량이 굉장히 커진다.
Write-back
가장 최신의 값이 메모리에 없고 다른 코어의 캐시에 있다. 따라서 자신의 것을 갱신하려면 다른 코어의 캐시에서 값을 받아올 때까지 기다리게 된다. 항상 메모리로 접근하는 Write-through보다 대역폭을 낮게 사용하지만 복잡하다.
Write-back이 비교적 비용이 적기 때문에 Write-back을 사용한다.
Write-back Snooping
- 어떤 프로세서가 값을 수정했다면 갱신된 값을 전파하는 것이 아니라 invalidate 메세지만 전파한다. 스누핑을 통해 모든 프로세서는 버스를 수신하고 있으므로 invalidate 이벤트는 모든 프로세서에게 전파된다.
- invalidate를 수신했다면 해당 invalidate된 메모리의 주소를 확인하여 캐시의 상태를 Invalid로 변경한다.
- 어떤 프로세서가 Invalid 상태인 캐시를 읽으려고 한다면, 해당 캐시의 주소와 함께 read 이벤트를 전파한다.
- 스누핑을 통해 모든 프로세서에게 전파되는데, 캐시 상태가 Invalid가 유효한 상태인 프로세서가 최신의 값을 다시 전파한다. 이 때 해당 캐시의 값이 최신으로 업데이트 된다.
FSM
Write-back snooping을 사용한다면 각 캐시의 상태를 FSM으로 표현할 수 있다. 이 때 CPU의 상태와 버스(메모리로 이해하면 될것 같다)의 상태를 나누어 표현한다.
CPU (코어)
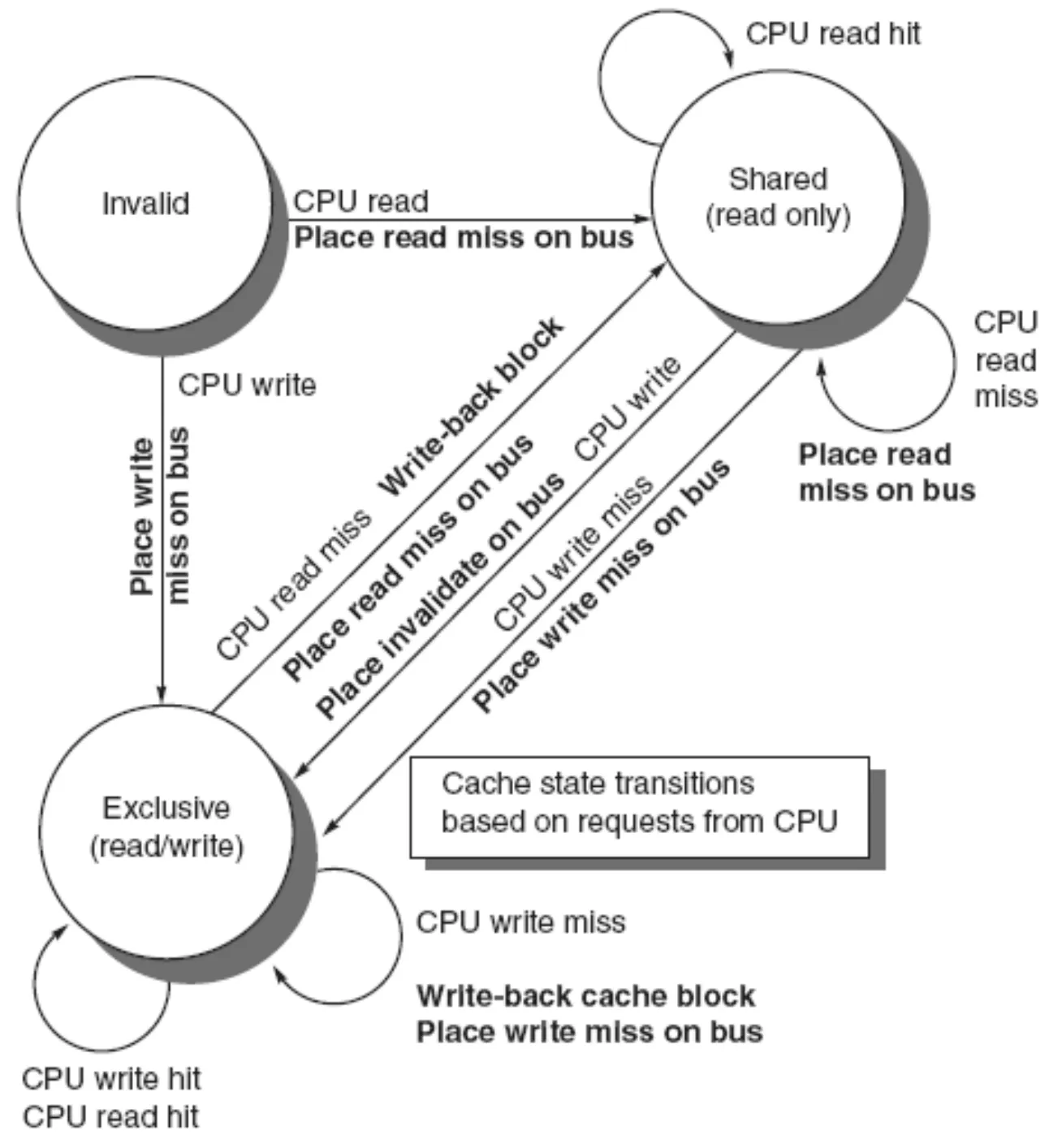
상당히 복잡하게 보여서 다음과 같은 표로 정리했다.
| 상태 | 액션 | 처리 | 다음 상태 |
|---|---|---|---|
| Invalid | Read miss | 값이 없으므로 read miss 송신, 메모리로부터 값을 읽어 저장 | Shared |
| Write miss | 없는 값에 쓰려고 하므로 값을 쓴 후 write miss 송신 | Modified | |
| Modified | Read hit | 최신의 값을 읽게 됨 | Modified |
| Read miss | 잘못된 주소를 읽으려 하므로, write miss를 송신 후 값을 가져옴 | Shared | |
| Write hit | 최신의 값으로 업데이트하게 됨 | Modified | |
| Write miss | 바꿨던 값을 다른 값으로 바꾸려고 하므로, 값을 바꾼 후 write miss를 송신 | Modified | |
| Shared | Read hit | 최신의 값을 읽게 됨 | Shared |
| Read miss | 찾는 값이 아닌 다른 값을 읽었으므로, 찾는 값을 메모리로부터 읽어온 후 read miss 송신 | Shared | |
| Write hit | 다른 캐시들에게 invalidate 송신, 새로운 값을 씀 | Modified | |
| Write miss | 다른 값에 쓰려고 하므로, write miss를 송신하고, 값을 씀 | Modified |
버스 (메모리)
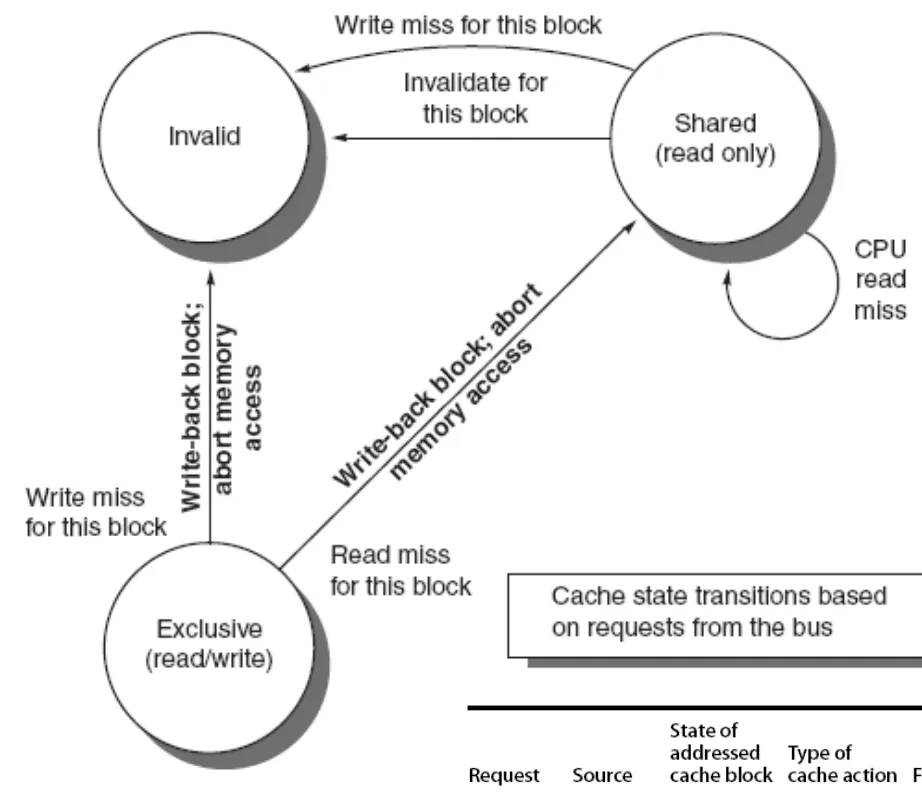
| 상태 | 액션 | 처리 | 다음 상태 |
|---|---|---|---|
| Modified | Read miss | 메모리에 있는 값이 최신이므로 이 값을 전파함 | Shared |
| Write miss | 메모리에 값을 쓰고 프로세서 캐시는 Modified로 만든 후 write miss를 전파함 | Invalid | |
| Shared | Read miss | 다른 프로세서가 일으킨 read miss이기 때문에 아무것도 하지 않는다 | Shared |
| Write miss | 어느 프로세서가 shared 상태에서 값을 썼기 때문에 write miss를 전파함 | Invalidate | |
| Invalidate | 해당 블럭을 invalid하라는 요청이므로 그대로 함 | Invalidate |
Cache miss
컴퓨터 구조에서는 3가지 캐시 미스가 있지만, 멀티코어환경에서는 한 가지가 더 추가된다.
버스를 통해 전달된 요청에 의해 캐시가 바뀌어서 invalidate된 상태다. 이 때 액세스 하려는 경우에 발생하는 캐시 미스다.
True sharing miss
같은 캐시 블럭에 데이터(A)가 있는데, 그 데이터(A)가 바뀜으로 해당 캐시 블럭 전체가 invalidate된 상태에서 그 데이터(A)를 액세스 하는 경우.
캐시 블럭이 1 word여서 데이터가 한 개밖에 없을 때 보통 발생한다.False sharing miss
같은 캐시 블럭에 데이터(A)가 있는데, 다른 데이터(B)가 바뀜으로 해당 캐시 블럭 전체가 invalidate된 상태에서 그 데이터를(A) 액세스 하는 경우.
캐시 블럭이 여러 word면 발생한다.
예시
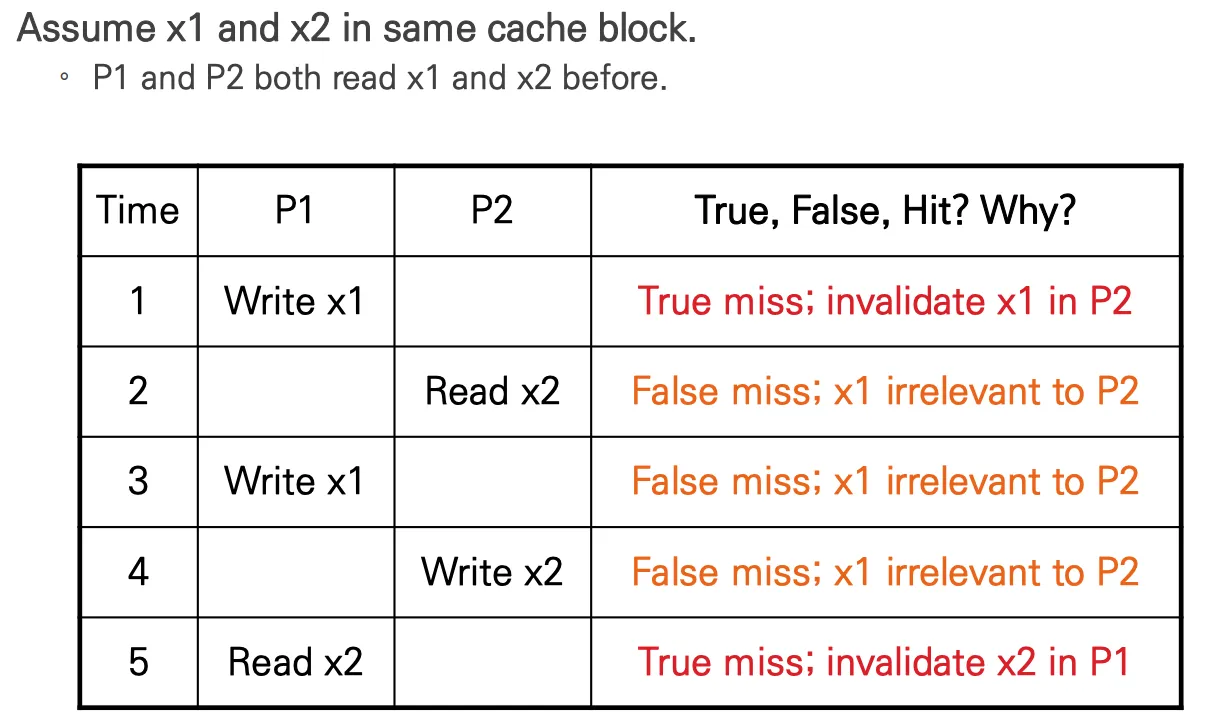
- P1이 x1에 쓰려고 하면, P1 캐시의 x1 modified가 되고, x1을 포함하는 캐시 블럭이 invalidate된다.
P2는 x1이 invalidate되었음으로 전달받기 때문에 true sharing miss다. - P2가 x2를 읽으려 하면, x1에 의해 invalidate된 캐시를 읽으려 하므로 false sharing miss다.
read miss가 발생하여 P1이 가진 최신의 값을 가져와 다시 shared 상태가 되도록 한다. - P1이 x1에 쓰려고 하면, P1 캐시의 x1은 modified로 변한다. 그리고 캐시 블럭은 invalidate된다. write miss가 발생하여 P2의 캐시에도 invalidate가 되어야 하는데, 원인이 x1이므로 false sharing miss다.
- P2이 x2에 쓰려고 하면, x1에 의해 invalidate된 캐시를 쓰려 하므로 false sharing miss다.
P2는 write miss를 보내고 자신의 캐시를 modified로 만든다. - P1이 x2를 읽으려 하면, 이미 4에 의해 캐시 블럭이 invalidate 된 상태에서 읽으려하므로 true sharing miss다.
Write-back Directory-based
디렉토리 기반 방식은 메모리 블럭마다 디렉토리 공간을 마련하여, 해당 메모리를 읽어간 모든 프로세서들을 기록한다음 이벤트가 발생할 때 목록에 있는 프로세서들에게 전파하는 방식이다.
프로세서마다 캐시를 사용하여 상태를 관리하게 된다. 프로세서는 각 캐시 블럭마다 dirty 비트를 추가해야한다. dirty 비트는 캐시에 있는 데이터가 수정되었는데 메모리에 반영이 되지 않은 상태를 의미하고, on이라면 캐시에 있는 데이터만 수정된 상태고 메모리에 반영이 안된 것을 말한다.
메모리에는 Presense 비트를 프로세서 수만큼 추가해야한다. Presence 비트는 해당 프로세서가 그 데이터를 갖고 있는 상태인지를 의미한다. 디렉토리 공간을 말한다.
- Read Event
- dirty 비트가 off일 때
값이 최신인 상태다. 메인 메모리의 값을 읽고 캐시에 복사한다.presence[i]를 on한다. - dirty 비트가 on일 때
다른 프로세서가 최신의 값을 갖고 있다. 캐시의 dirty 비트가 on인 프로세서를 찾아 자신의 메모리를 업데이트한다. 그 다음 값을 읽고presence[i]를 on한다.
- dirty 비트가 off일 때
- Write Event
- dirty 비트가 off일 때
최신의 상태일 때 쓰기를 하려고 하므로,presence가 on인 프로세서들에게 invalidate를 전파한다.
자신의 dirty 비트를 on하고 값을 쓴다.presence[i]도 on으로 변경한다. - dirty 비트가 on일 때
다른 프로세서가 최신의 값을 갖고 있고 자신은 그렇지 않은 상태다. 캐시의 dirty 비트가 on인 프로세서를 찾아 자신의 메모리에 업데이트한 후 값을 쓴다. 자신의 dirty 비트를 off한다.presence[i]도 on으로 변경한다.
- dirty 비트가 off일 때
FSM
스누핑 방식에 사용된 MESI와 비슷하지만 3가지 상태만 존재한다.
| 상태 | 설명 |
|---|---|
| Shared | 1개 이상의 프로세서가 최신의 값을 가지고 있는 상태 |
| Uncached | 어느 프로세서도 갖고 있지 않은 상태 |
| Exclusive | 하나의 프로세서만 최신의 값을 가진 상태 (메모리에 있는 값은 오래된 값) |
스누핑 방식에서는 CPU와 버스만 프로토콜에 참여하지만, 여기서는 3가지 유형의 프로세서가 관여한다.
- Local node : 요청을 보낸 프로세서
- Home node : 요청에 해당하는 메모리를 갖고 있는 프로세서
- Remote node : 홈 노드로부터 복사본을 갖고 있는 프로세서 (Exclusive 또는 Shared와 유사)
CPU (코어)
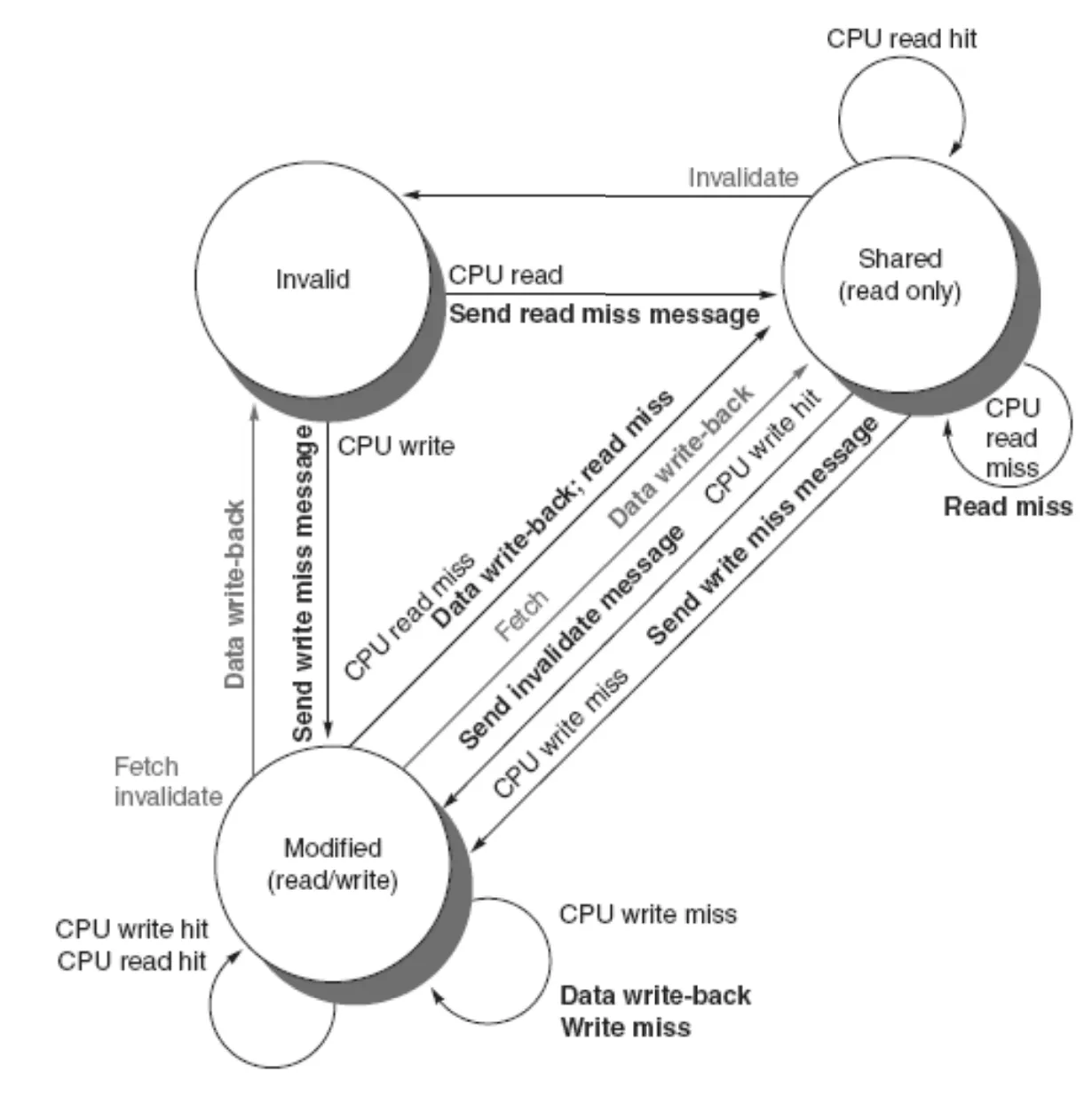
| 상태 | 액션 | 처리 | 다음 상태 |
|---|---|---|---|
| Invalid | Read miss | 캐시에 값이 없으므로 Read Miss 메시지를 송신하고, 메모리에서 값을 가져와 캐시에 저장 | Shared |
| Write miss | 캐시에 값이 없으므로 우선 Write Miss 메시지를 송신하여 메모리에서 데이터를 가져온다. 캐시에 저장 후 값 수정 | Modified | |
| Shared | Read hit | 캐시에 최신 값이 있으므로 그냥 캐시에서 최신 값을 읽음 | Shared |
| Read miss | 다른 프로세서가 값을 요청할 때 발생. 내 캐시에서 값을 다른 프로세서에게 제공한다 | Shared | |
| Write hit | 값을 수정하고나면 다른 프로세서의 값은 비활성화 해야하므로 Invalidate 메시지를 송신한다 | Modified | |
| Write miss | 이미 캐시되어 공유되고 있는 블록에 다른 메모리의 값을 쓰려고 할 때 발생, 다른 프로세서들에게 write miss를 전송하고 새로운 데이터 씀 | Modified | |
| Modified | Read hit | 캐시에 최신 값이 있음. 캐시에서 최신 값을 읽음. | Modified |
| Read miss | 다른 프로세서가 값을 요청하여 read miss가 나에게 전달된 상태, Write-Back으로 내 캐시 속 데이터를 다른 프로세서에게 전달 | Shared | |
| Write hit | 현재 캐시가 값을 보유. 캐시의 값을 업데이트. | Modified | |
| Write miss | 다른 프로세서가 값을 쓰려고 할 때 나만 modified 상태라면 발생. Write-Back으로 다른 프로세서에게 값을 전달한 뒤, 그 프로세서가 값을 수정하여 저장한다면 내 캐시는 invalid되어야 함 | Modified |
디렉토리
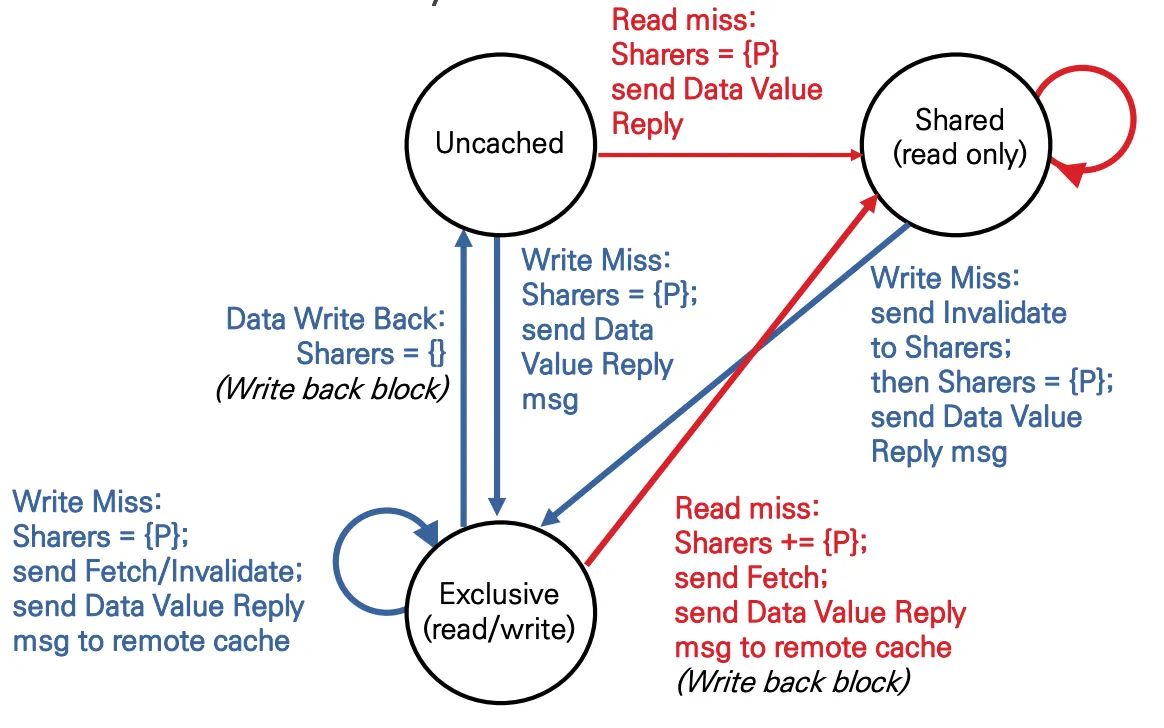
| 상태 | 액션 | 처리 | 다음 상태 |
|---|---|---|---|
| Uncached | Read miss | presence(위 사진에서 Sharer)비트에 프로세서를 추가한 다음 데이터를 전송 | Shared |
| Write miss | presence비트에 프로세서를 추가한 다음 쓰기 작업 진행 | Exclusive | |
| Shared | Write miss | 쓰기를 하려고 한다면 일단 데이터를 갖고 있는 프로세서들을 전부 invalid시킨다. 그 다음 데이터를 씀 | Exclusive |
| Exclusive | Read miss | 데이터를 썼던 프로세서만 값을 갖고 있으므로 그 데이터를 요청, presence 비트에 프로세서를 추가한 다음 값을 읽어서 갱신하고, 값을 갖고 있는 다른 프로세서들에게 전파 | Shared |
| Write miss | 내가 데이터를 써서 Exclusive된 메모리에 다른 프로세서가 데이터를 쓰려고 할 때 발생, 나에게 invalid 메세지가 전달된다. 그 다음 다른 프로세서가 값을 쓰게 됨 | Exclusive | |
| Data Write Back | 데이터가 캐시에서 제거됨? | Uncached |
'대학교 공부 > 멀티코어프로그래밍' 카테고리의 다른 글
| 멀티코어프로그래밍 (5) - OpenCL 프로젝트 최적화 (0) | 2025.06.14 |
|---|---|
| 멀티코어프로그래밍 (4) - OpenCL 프로젝트 후기 (0) | 2025.06.14 |
| 멀티코어프로그래밍 (3) - [논문 리뷰] Extending Amdahl’s Law for Energy-Efficient Computing in the Many-Core Era (0) | 2025.06.14 |
| 멀티코어프로그래밍 (1) - 멀티코어 아키텍쳐의 대두 (0) | 2025.06.14 |
댓글